In den letzten Jahren hat sich der Blick auf das Bereich des Machine Learnings stark verändert. Obwohl Machine Learning bereits seit mehreren Jahrzehnten existiert, so hat dieses Gebiet spätestens in den letzten 10 Jahren die wissenschaftliche Nische verlassen und ist auch in der breiten Öffentlichkeit bekannt – ebenso wie das noch ältere Feld der künstlichen Intelligenz, dessen englischsprachiger Begriff Artificial Intelligence (AI) bereits in den 1950er eingeführt worden ist.
Die größer werdende Bekanntheit des Machine Learnings hat viele Ursachen: Zum einen liegt dies an der Entwicklung im Bereich der Hardware durch schnellere Prozessoren und größer werdende Speicher, die je Speichereinheit sogar erheblich günstiger geworden sind. Zum anderen hat in den vergangenen Jahren auch eine Weiterentwicklung bei der Algorithmik eingesetzt, die den Einsatz vieler Machine Learning-Verfahren erst praxistauglich gemacht hat.
Die Vorgehensweise beim Machine Learning drückt sich schon sehr prägnant im Namen aus: Vor dem Einsatz von Machine Learning-Methoden muss das Programm angelernt werden. Dafür sind viele Datensätze nötig, so dass die Maschine auf die „richtigen“ Lösungen trainiert werden. Auch zeigt sich, warum Machine Learning hat in den letzten Jahren an Fahrt aufgenommen hat: Erst in den letzten Jahren bzw. Jahrzehnten ist es möglich gewesen, die dafür nötigen großen Datenmengen zu erheben und zu speichern.
Durch das Internet ist es auch möglich geworden, eine Vielzahl von Open Source-Bibliotheken zur Verfügung zu stellen, mit deren der Einsatz von Machine Learning und Deep Learning praktisch angewendet werden. Insbesondere in der Programmiersprachen Python und R haben sich viele solcher Bibliotheken wie Keras/Tensorflow, PyTorch, scikit-learn herausgebildet (vgl. https://www.kaggle.com/kaggle-survey-2021).
Die technische Seite bei der Verwendung von Machine Learning ist allerdings nur ein Aspekt. Viel tiefgreifender ist die Tatsache, dass der Einsatz von Machine Learning-Verfahren auch die Schwerpunkte der Arbeit verlagert. Während bislang die Implementierung der Zusammenhänge im Vordergrund stand, wird dies von Machine Learning-Methoden durch Lösen von Optimierungsproblemen übernommen.
Andere Gesichtspunkte werden hingegen relevanter: Damit das Modell die gewünschten Zusammenhänge erkennen kann und keine falschen Schlüsse zieht, ist die Güte der zugrundeliegenden Daten sicherzustellen. Aber auch neben der Datenqualität erfordert das Verständnis der Ergebnisse besondere Aufmerksamkeit. Machine Learning-Verfahren bewirken daher auch eine Veränderung der Prozesse, verlagern Aufgabenschwerpunkte und verändern Rollen.
Einstieg in die versicherungstechnische Praxis
Wir haben den Einsatz von Machine Learning im aktuariellen Versicherungsumfeld erprobt. Um auf dem Feld Erfahrung zu sammeln, wenden wir einen Fall aus der Lebensversicherung an.
Als Ziel wird eine Menge an künstlichen Verträgen erzeugt, die für ein festgelegtes Risikolebensversicherungs-Produkt den jeweiligen Nettobeitrag auf Basis von
- Eintrittsalter
- Geschlecht (Bisex-Kalkulation)
- Todesfallleistung
- Versicherungsdauer (=Beitragszahlungsdauer)
bestimmen sollen.
Man könnte diese Problemstellung in einer praktischen Anwendung bspw. dafür einsetzen, Verträge zu erkennen, deren Beitrag mit einer gewissen Wahrscheinlichkeit nicht korrekt ist.
Im weiteren Verlauf wird das Ergebnis des Prototyps vorgestellt.
Als Ausgangspunkt für das Maschinelle Lernen wurde ein künstlicher Testbestand aufgesetzt. Es wurde eine Anzahl von Verträgen festgelegt und zu Beginn ein Eintrittsalter für jeden „Vertrag“ zufällig bestimmt. Es wurde dabei angenommen, dass die Verteilung über die Eintrittsalter Poisson-verteilt mit 𝜆=35 , also die zugehörige Zufallsvariable 𝐴 besitzt die Verteilung 𝐴∼𝑃(35) . Letztlich wurden nur Alter zwischen 20 und 55 Jahren akzeptiert, übrige Alter werden nachträglich verworfen, um sinnvolle Eintrittsalter zu verwenden.
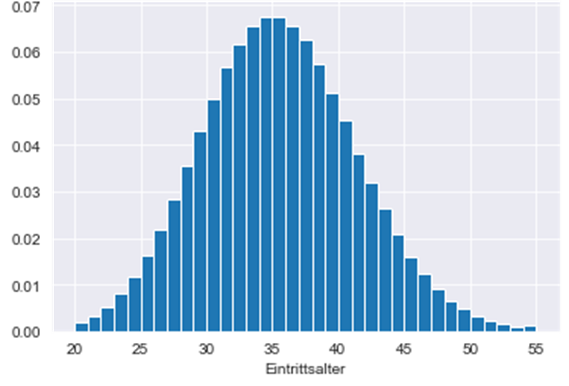
Für jeden der erzeugten Datensätze zum Eintrittsalter wird ein minimalistischer „Vertragssatz“ nach folgenden Kriterien erzeugt:
- Geschlechter-Ausprägungen weiblich und männlich sind zufällig mit Wahrscheinlichkeit 50% erzeugt worden
- Versicherungsdauer ist per Gleichverteilung im Intervall [5, 65 – Eintrittsalter] ermittelt worden
- Rechnungszins = 2,25%
- Ausscheideordnung = DAV2008T
- Kalkulationsart = Bisex
- Todesfallleistung ist gleichverteilt in 5.000er-Schritten im Intervall [50.000, 345.000] angesetzt worden
- Einzelvertragliche Nettobeitragskalkulation über Äquivalenzprinzip mit bekanntem Barwert-Ansatz per Leistungsprimat:
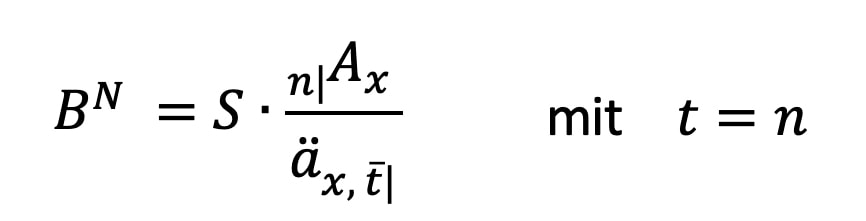
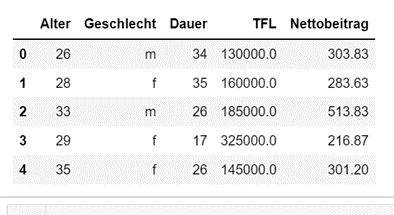
- Im folgenden Szenario wurde ein Datensatz mit 2.000.000 Einträgen erzeugt, davon wurden 1.993.955 Datensätze nach Selektion der Eintrittsalter akzeptiert.
Für die Praxis sollte dies keine Einschränkung darstellen, da es häufig auch Referenzrechner (über Excel oder andere Programme) gibt, mit denen sich auch beliebig viele Datenmengen erzeugen lassen sollten.
Im nachfolgenden Schritt wurden mehrere Machine Learning-Methoden auf den Datensatz angesetzt. Neben der recht simplen linearen Regression wurden auch Methoden wie Support Vector Machines (SVM), Random Forest und Gradient Boosting angewendet. Sowohl mit Blick auf Genauigkeit, aber auch hinsichtlich der Zeit, die benötigt wird, um das Modell zu trainieren, scheint die Verwendung neuronaler Netze am vielversprechendsten.
Neuronale Netze stammen aus einem Teilgebiet des Maschinellen Lernens, dem sog. Deep Learning. Bei dieser speziellen Art findet das Lernen in mehreren Schichten (engl. Layers) statt, die miteinander interagieren. Diese Funktionsweise ist angelehnt an den Aufbau des menschlichen Gehirns.
Auf Basis eines neuronalen Netzes, welches mit einem Teil des oben beschriebenen Datensatzes trainiert worden ist, wurde mit dem verbliebenen Teil eine Vorhersage durch das Modell erstellt. Da die richtigen Werte bekannt sind, kann man die Güte des Modells überprüfen. Dies wird im unten dargestellten Graph gemacht: Graphisch dargestellt ist auf der horizontalen Achse der tatsächliche Wert für die Nettoprämie, auf der vertikalen Achse der vom neuronalen Netz vorhergesagte Nettobeitrag – einmal bezogen auf die gesamte Testdatenmenge (links), einmal mit feinerer Auflösung im ausgewählten Bereich zwischen 240 und 250 Euro jährlichem Nettobeitrag.
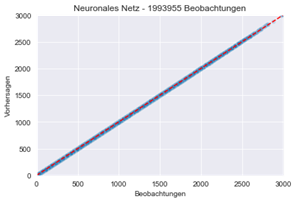
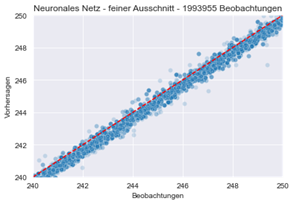
Abbildung 4: Auswertung des neuronalen Netzes anhand von Actual vs. Predicted-Plots mit unterschiedlicher Auflösung
Idealerweise sollten sich die Punkte auf der rot gestrichelten Linie befinden. Auch im fein skalierten Ansatz wird deutlich, dass das neuronale Netz in der Mehrzahl der Fälle den jeweiligen Nettobeitrag recht genau ermitteln kann.
Es gibt auch einige Punkte, die von der rot gestrichelten Linie abweichen. In diesen Fällen sind die Vorhersagen noch nicht zufriedenstellend. Hier wird im Folgenden durch weitere Optimierung des neuronalen Netzes versucht, eine Verbesserung der Modellgüte herbeizuführen.
Fazit
Mit der vorgestellten Problemstellung wurde versucht, im Bereich Machine Learning Erfahrungen und Erkenntnisse zu sammeln, mit deren Hilfe ein praktischer Nutzen im Versicherungsumfeld erreicht werden kann. Eine Möglichkeit zur Nutzung durch Ausbau dieses prototypischen Ansatzes könnte eine Validierung eines Teilbestandes sein, um Verträge zu identifizieren, deren Beitrag mit einer gewissen Wahrscheinlichkeit fehlerhaft ist.